Building a Recommendation Engine with Collaborative Filtering
At America’s Test Kitchen, our engineering team spends two days every quarter participating in Professional Development Days - a hackathon-esque opportunity for each of us to build something cool and learn new things. My recipe recommender proof-of-concept was a product of our last professional development cycle.
The Challenge
Our recipe pages currently list manually curated links to related content
(see the ‘More From Cooks Illustrated’ section at the bottom of this page).
This usually includes articles on equipment or ingredients needed to make the
recipe, or suggested accompaniments and variations that were listed with the
recipe in the magazine.
My goal was to supplement the manually curated related content with a feature
similar to the “Users who bought this item also bought these items” section
on Amazon’s product pages.
In theory, this would keep readers more engaged by giving them
an easy way to browse to new recipes without having to navigate back to a home
page or searching for a new term.
The Solution
I started by researching the techniques used by existing recommendation engines. I found that many of them used a machine learning concept called collaborative filtering, which involves leveraging user’s likes or dislikes to measure the similarity of elements in a dataset. The assumption this technique makes is that items which are ‘liked’ by a similar set of users are similar themselves. An example of a collaborative filtering is Facebook’s “People you may know” feature, which generates predictions under the assumption that people with a similar set of friends are likely to know each other.
Collaborative filtering was the perfect technique to build the recommendation engine. We already had a huge dataset of User Favorites - a feature that allows users to save recipes they cooked or plan to cook for later viewing. I realized I would be able to use this data to compare the sets of users who favorited each pair of recipes and determine their similarity. Each recipe page would recommend the recipes with the greatest similarity.
The Algorithm
In order to implement the collaborative filtering technique, I needed an algorithm to determine the similarity of sets. I found a statistic called the Jaccard Coefficient that scores the similarity of two sets by dividing the cardinality (length) of their intersection set by the cardinality of their union set.
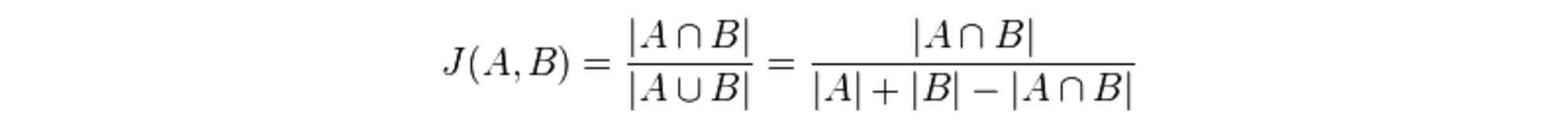
I used the Jaccard Coefficient to build a matrix of similarity set scores. For each permutation of recipe pairs, the similarity of each recipe’s set of “favoriters” was calculated.
Recipe.each do |x_recipe|
Recipe.each do |y_recipe|
similarity_matrix[x_recipe][y_recipe] = jaccard_coefficient(
x_recipe,
y_recipe
)
end
end
# cardinality of intersection / cardinality of union
def jaccard_coefficient(left, right)
(left.favoriters & right.favoriters).length /
(left.favoriters | right.favoriters).length
endOnce the matrix was built, recommendations for a given recipe could be generated by looking up the recipes which had the highest similarity in the given recipe’s row.
def generate_recommendations(recipe, number_of_recommendations)
similarity_matrix[recipe].max_by(number_of_recommendations) do |key, value|
value
end
endAdding some context
Collaborative filtering alone wasn’t enough. With user favorites as the only metric for determining recipe similarity, I found that the recommendations I was generating weren’t very helpful. For example, when viewing the Chocolate Crinkle Cookies recipe, you might see a recommendation for Chicken Noodle Soup because many of the same users just happened to have favorited both recipes. The recommendation engine was really just showing content that was popular, and to a user, it would just look like we were displaying random recipes on the page.
To add some context to the recommendations, I applied the Jaccard Index technique to data from our recipe tagging system. Recipes were scored for tag similarity across 3 different categories: Dish Type, Main Ingredients, and Recipe Type. I then combined the similarity scores from these 3 new datasets with the user favorites similarity data using a 6 point system:
| Similarity Set Metric | Examples | Points Possible | ||||||
|---|---|---|---|---|---|---|---|---|
| Favoriters | Users 1, 5, 7, 9 | 3 | ||||||
| Dish Type | Salads, Breakfast, Breads | 1 | ||||||
| Main Ingredient | Chocolate, Beef, Vegetables | 1 | ||||||
| Recipe Type | Vegetarian, Quick and Easy, Grilling and Barbecue | 1 |
By bringing in those new datasets, the recommendation engine was able to make suggestions of recipes that were both relevant and popular.